Methods Overview
Atropos Health provides personalized evidence for clinical decisions based on real-world data. Depending on the clinical questions posed and data availability, we use different study designs and analysis methods to provide real-world evidence in the form of our proprietary prognostograms. One of our key goals is to provide timely evidence, so we have optimized our observational studies to be completed within 48 hours. Below we describe the various study designs and analysis methods available on Atropos Health.
Case report and case series
A case report usually describes a single patient, providing his/her demographics, comorbidities and outcomes. Such case reports provide noteworthy observations, typically for new diseases (e.g. COVID-19) when symptoms and pathology of the disease are yet to be established. An example is a case report of one of the first known patients reinfected with COVID-19.
A case series is a collection of many case reports to give a descriptive summary of a group of patients. For example, this case series provided the demographic and clinical characteristics of 24 patients first diagnosed with COVID-19 in Seattle.
Analysis
Both case reports and case series are descriptive studies that provide summary statistics. Their purpose is to summarize relevant clinical features from a case or a group of cases. These studies do not have a control or comparison group, so they are not used to test whether a particular intervention is safe or effective. Case reports and case series provide useful exploratory analysis that can lead to clinically relevant hypotheses that might later be tested using a different study design.
In an Atropos Health case series, clinical outcomes are statistically summarized as follows depending on the type of outcome:
| Type of outcome | Example | Reported as |
| Binary | Infected or not | Number (N) and percentage of occurrences in the study sample. e.g. Infection rate: 23 (12.3%) |
| Continuous | Lab value | Mean and standard deviation e.g. BMI: 25.3 (10.1) |
| Survival | Death Time to relapse |
1) Number (N) and percentage of occurred events out of the entire cohort e.g. Death: 13 (12.3%) 2) Either median survival time or median follow-up time. If the median event-free survival time can be defined, we report that. If not, we report the median number of days that subjects were followed for each survival outcome. e.g. Median survival time (days): 1,260.5 3) Restricted mean follow-up time (RMST). This is the average event-free survival from when we started observing patients until we stopped observing patients. E.g. RMST (days): 3478.4 |
Output
The case series design provides a demographics figure and table summarizing: population size, demographics (gender, age, race, index year when the condition of interest occurred), pre-index comorbidities, mean pre-index history, mean post-index followup, and the outcomes that occur therein. Outcomes are summarized using the above descriptive statistics and also plotted.
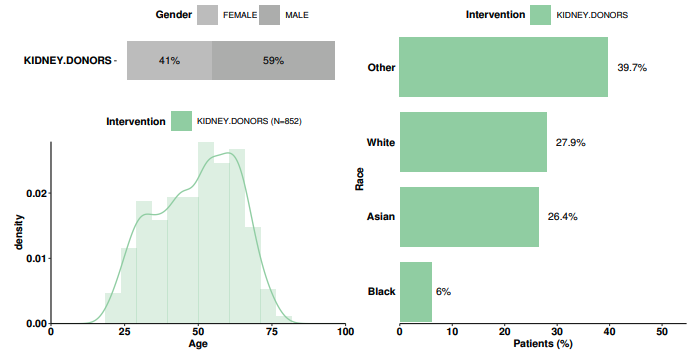
Sample demographics figure for case series
Subgroups
We consider subgroups as multiple case series where a descriptive summary is provided for each case series group. Thus, the analysis and output will be similar to that of case series except repeated for multiple groups (see Case Series above). As in case series, no statistical comparisons are performed.
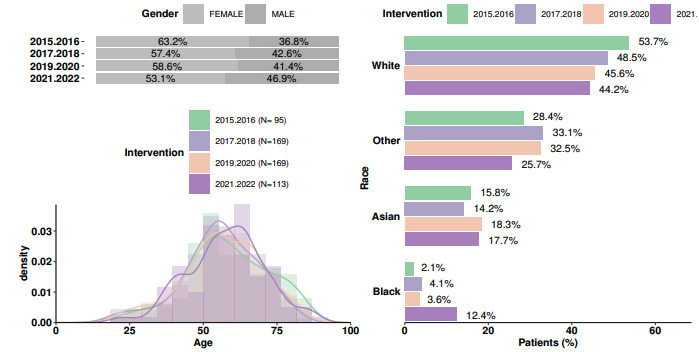
Sample demographics figure for subgroups
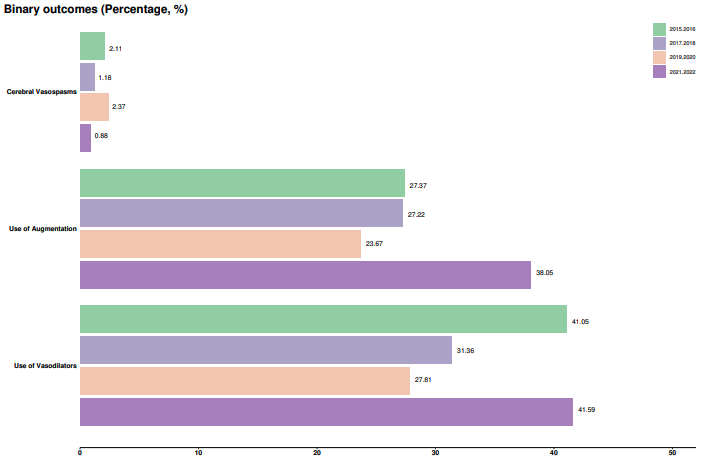
Sample outcomes figure for subgroups
Cohort study
This is the most common observational study design. Its popularity stems from its intuitive structure for comparing patients who have received different medical treatments (e.g. Drug A vs Drug B). In a cohort design, the researchers identify groups of patients based on what treatment those patients received. These groups are observed over time to see what outcomes they develop. These outcomes are then compared between the treatment groups. Unlike in a clinical trial, the researchers do not assign treatments to patients. Rather, the researchers observe which treatments the patients received. Because treatment assignment is not randomized, underlying differences between the comparison groups cannot be evened out by random sampling. Instead, it is possible that any apparent effect of the treatment on the outcome could be confounded - it could be due to other patient characteristics instead. Nevertheless, careful design and analysis can minimize these differences and allow researchers to estimate treatment effects with confidence and to make causal inferences.
Analysis
In a cohort study at Atropos Health, we use propensity score matching (PSM) as a method to control for possible confounding. PSM aims to balance the pre-treatment differences between treatment groups so that the groups are as similar as possible before their treatment assignments. To that end, we compute a propensity score that summarizes the pre-treatment characteristics of each patient. The propensity scores stem from a model where each patient’s treatment assignment is predicted by potential pre-treatment confounders as explanatory variables:
log PS / 1-PS ~ pretreatment covariates where PS = probability of treatment
After calculating each patient’s probability of treatment (a.k.a propensity score), we balance the treatment groups by matching patients based on these probabilities within a caliper beyond which a match is considered too distant to be valid.
We then compare outcomes between these balanced or matched groups. Outcome differences between groups can be said to be attributed to the treatment if the PSM was successful. There may be some residual confounding even after PSM. Residual confounding may arise because the propensity score model may not perfectly explain the measured confounders and some confounders may remain unmeasured (e.g. smoking status is unavailable or not specified to be a confounder).
An Atropos Health prognostogram includes a balance table for each outcome that shows the distribution of patient characteristics before and after PSM. This allows readers to see how successful PSM was at balancing out patient characteristics between groups. The standardized mean difference between treatment levels for each potential confounder is computed; variables where the difference is above the threshold of 0.25 are highlighted to help in visual inspection (Stuart et al. 2013).
In a cohort study, clinical outcomes are statistically compared as follows.
| Type of outcome | Univariate | Multivariate |
Binary, e.g. infection |
Chi-square Fisher’s exact (if 1-5 counts in any cell) Not computed if 0 counts in any cell (i.e. perfect separation or underpowered) |
Logistic regression Fisher’s exact (if 1-5 counts in any cell) Not computed if 0 counts in any cell (i.e. perfect separation or underpowered) |
Continuous (normal), e.g. BMI |
Welch’s test (does not require equal variance assumption) | Linear regression |
Continuous (non-normal), e.g. pain score, duration |
Mann-Whitney U-test This non-parametric test compares ranks and not actual values. Thus, it is robust to extreme values in non-normal distributions. (Non-normality is determined by Shapiro-Wilk test where p-value < 0.1) |
NA |
Discrete, e.g. number of visits |
Hurdle negative binomial regression | Hurdle negative binomial regression |
Survival, e.g. time to death |
Cox proportional hazards regression | Cox proportional hazards regression |
Statistical significance is denoted by p-value < 0.05. To address residual confounding, we also report E-value. E-value, as a measure of causality, quantifies how strongly associated a hypothetical residual confounder has to be with both treatment and outcome to nullify the observed effect. Thus, a large E-value indicates that a very strong residual confounder would be required in order for the observed effect to be caused by this hypothetical confounder. Such a strong association is generally unlikely, which strengthens our conclusion that the observed association is causal.
Output
Key output includes a summary table of patients’ baseline characteristics as in Case Series, as described above. Statistical comparison of outcomes are reported as effect size along with their 95% confidence intervaI and p-value.
Effect size table
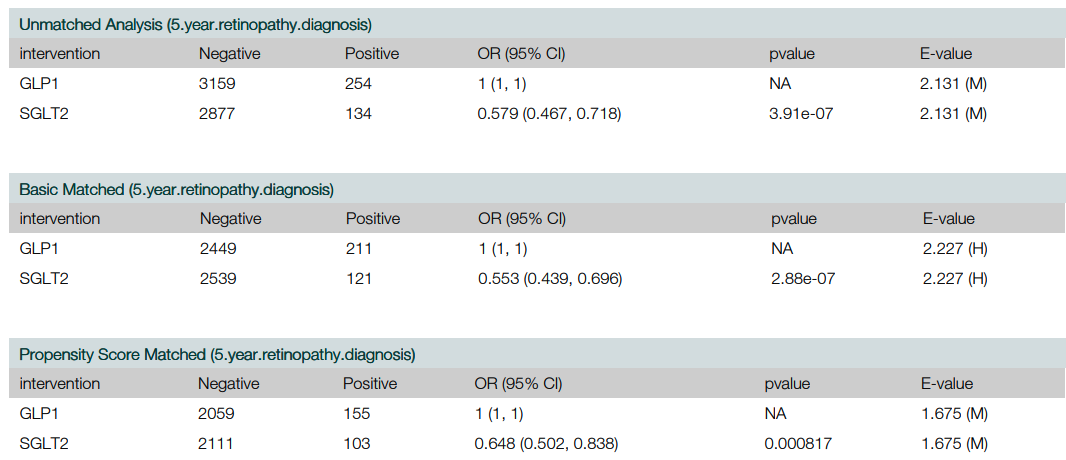
Sample effect size table for cohort study
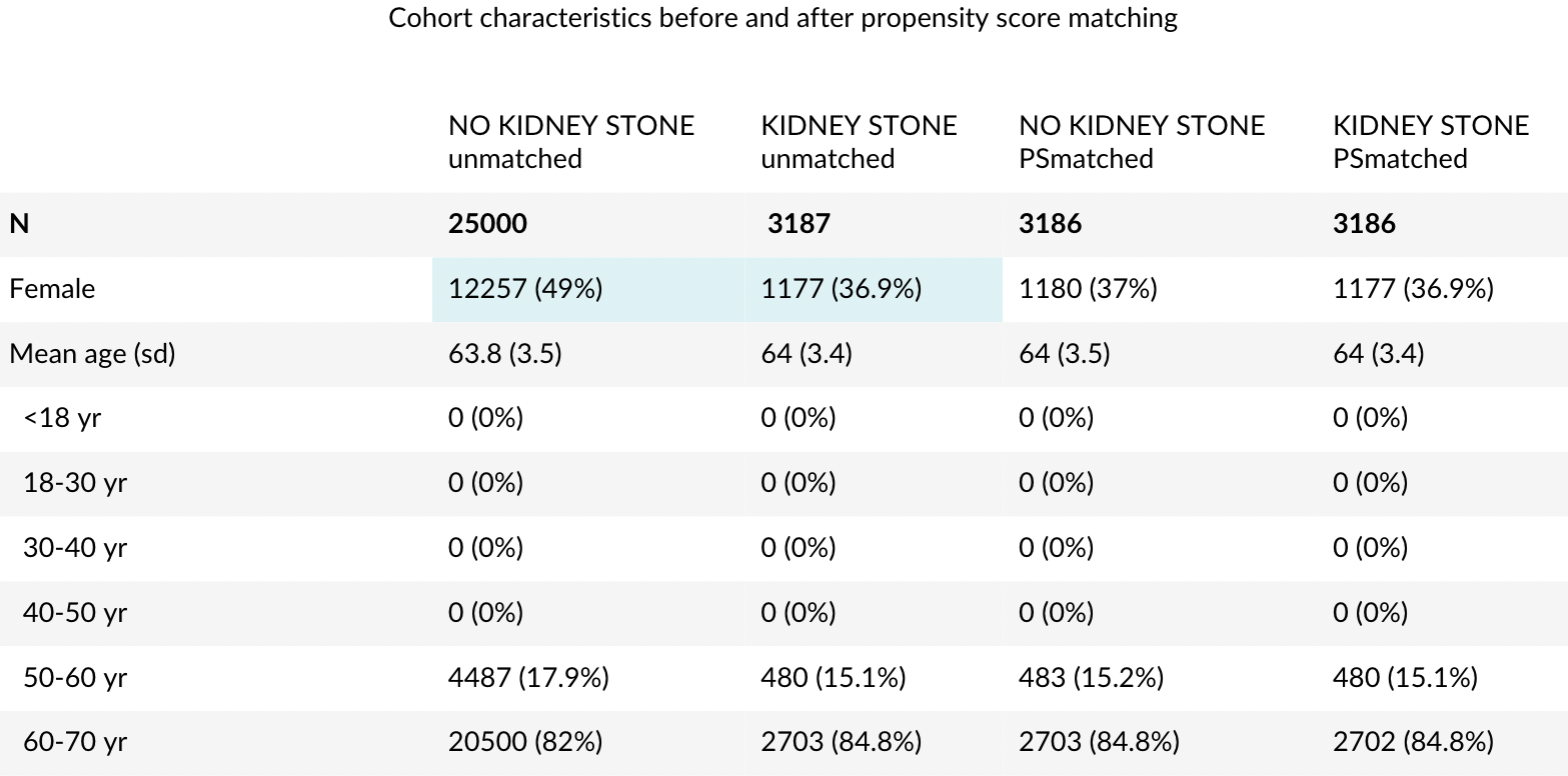
Balance table
The balance table shows how pre-treatment patient characteristics differ between treatment before and after PSM. Unbalanced characteristics with large differences (>0.25, Stuart et al. 2013) are highlighted. In the example below, we see that the percentage of female patients with an initial absolute difference of over 10% became balanced after PSM (0.01% absolute difference).
Propensity score supplemental information
Additionally, propensity score model fit is available upon request.
Note that the following model fit showed that the propensity score model was well fitted with 94% AUC and had its most positive and negative variables as gender, age, comorbidity score and ICD9 and RX codes indicative of enteritis and ulcerative enterocolitis.
These heavily weighted variables also coincided with the pre-treatment variables (%female, age and comorbidity score) that became balanced between the 2 treatment groups after PS matching (see Balance table example above). Such supplemental information about the PS model fit and the balance impact of the PS matching corroborate that our confounder adjustment has been reasonably performed.
Sample balance table for cohort study
Sample propensity model fit diagnostics
"auc": 0.9364,
"call": {
"class": "glmnet",
"x": "X",
"y": "y",
"weights": "weights",
"alpha": "1",
"family": "binomial",
"nlambda": "100",
"standardize": "F",
"maxit": "1e+05"},
"lambda": 0.0017,
"coeff": {
"(Intercept)": -3.227,
"log_charlson_score": -1.3929,
"gender.female": -0.4112,
"age_std": -0.3408,
"log_CPT": -0.2514,
…
"ICD9_555.9_frequent": 1.0745,
"log_ICD10": 1.0927,
"RX_8640_once": 1.2298,
"ICD9_555.1_once": 1.3168,
"ICD9_555.2_once": 1.4805,
"ICD9_555.0_once": 1.4914,
"ICD9_556.9_sporadic": 1.756,
"ICD9_555.9_sporadic": 1.7906,
"RX_1256_once": 1.9717,
"ICD9_556.9_once": 2.8087,
"ICD9_555.9_once": 4.0965}
Case-control study
The case-control is less commonly used than the cohort study. Unlike a cohort study which compares patients of 2 different treatments (e.g. drug A vs drug B), a case-control compares patients of 2 different disease status (disease vs healthy). The case-control disease looks back in time from the outcome status to observe if there were risk exposures more likely in one group than the other. For example, lung cancer cases were found more likely than healthy controls to have been exposed to cigarette and coal fumes. Such a case-control design famously established smoking as a cause of lung cancer (Doll & Hill 1950).
At Atropos Health, we implement a nested case-control study design. First, we define a cohort of eligible patients based on some criteria (e.g. being tested for COVID-19). Within that cohort we sample a group of cases that are defined by their outcome status (e.g. tested COVID-19 positive) and a group of non-cases (e.g. tested negative) as controls.
Analysis
Odds ratios are typically reported for case-control studies and computed using multivariable logistic regression where the dependent variable is the outcome status and the explanatory variables are the risk exposures. Briefly, odds ratios are a proxy for how much more likely cases will occur than controls per unit increase in the risk factor.
For example, a case-control study of COVID-19 among healthcare workers identified cases as workers with COVID-19 symptoms who tested positive for SARS-CoV-2, compared to controls who had similar symptoms but tested negative. That study found that workers in housekeeping, patient support, and nursing staff were at higher risk of COVID-19 than administrative staff (i.e. OR > 1.0) (Carazo et al. 2022).
Self-controlled case series (SCCS)
Like the cohort and the case-control designs, the purpose of an SCCS study is to determine whether a particular treatment increases (or decreases) the risk of a particular outcome in the population. The unique feature of an SCCS study is that the design includes only “cases” - patients who experienced the outcome of interest. Instead of comparing disease risk between treatment groups (as a cohort study) or exposure prevalence between cases and controls (as a case-control study), an SCCS study compares the rate of outcomes during time periods when patients are exposed to a treatment vs. the rate when they are not exposed. In effect, cohort and case-control studies ask the question, “why me?” - why did the outcome happen to one patient and not another? Was it due to which patients received the treatment of interest? In contrast, an SCCS study asks the question, “why now?” - why did the outcome happen at the time it did for a particular patient? Was it due to when that patient received the treatment of interest?
For example, if a researcher was interested in whether measles-mumps-rubella (MMR) vaccine may increase the risk of aseptic meningitis, an SCCS study would only include patients with newly diagnosed aseptic meningitis.
This figure illustrates a hypothetical group of four patients in an SCCS study of MMR vaccine (“exposure”) and aseptic meningitis (“event”). The study begins by identifying patients with aseptic meningitis between the ages of 365 days and 665 days. For these patients, the researchers then identify any MMR vaccines received. It is conjectured that MMR vaccine could increase the risk of aseptic meningitis during the subsequent 60 days. For each patient, the time from receiving the vaccine until 60 days later is considered “exposed” person-time, and other time periods are considered “unexposed” person-time. The SCCS study will compare the rate of event (i.e. aseptic meningitis) during exposed person-time to the rate during unexposed person-time.
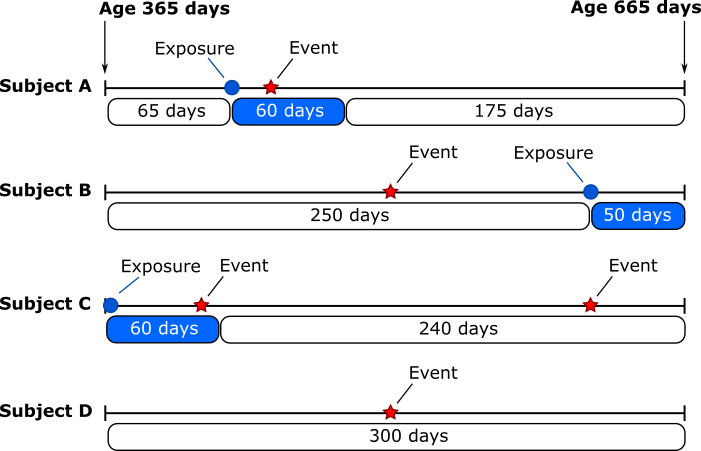
One benefit of the SCCS design is that comparisons are made within individuals - for each individual, the rate of outcomes between exposed person-time is compared to the rate during unexposed person-time. Because the comparisons are within individuals (i.e. “self-controlled”), the SCCS study will not be biased due to individual-level features that do not change over time, such as race or sex and is a great alternative to the cohort design when inter-individual confounding is too great to be overcome with existing causal methods.
In contrast with the SCCS which compares event rates within the same individual at different times (exposed vs unexposed), a cohort design compares the event rates between a group of patients who received MMR vaccine and a group that did not, and would compare event rates of aseptic meningitis between the two groups. Another two-group study design is the case-control design which would compare a group of individuals with aseptic meningitis (i.e. cases) with another group without (i.e. controls).
Analysis
Incidence rate ratios (IRRs) are typically reported for SCCS studies. These are computed using conditional Poisson regression where the dependent variable is the outcome status and the explanatory variable is the exposure of interest. By design, the method controls for fixed individual characteristics such as race and sex. If desired, additional variables can be included in the regression model to account for time-varying characteristics that may be related to the exposure and the outcome.
As an example, Ikuta and colleagues used an SCCS design to estimate the association between use of proton pump inhibitors (PPIs) and risk of acute kidney injury. Among 766 patients with acute kidney injury (defined based on serum creatinine levels), they estimated that acute kidney injury was 1.8 times more frequent (95% CI, 1.6 to 2.0) when patients were using PPIs compared to when the patients were not using PPIs (Ikuta et al. 2022).