Glossary
Metrics used in Evidence-Based Deliverables
Effect size
Effect size measures the strength of the relationship between two variables in a study. Depending on the type of the outcome and the statistical comparison method, effect size can be expressed as odds ratio, hazard ratio, incidence rate ratio, or standardized mean differences. For more details, refer to the review paper by Tripepi et al. 2007.
Standardized mean difference
The standardized mean difference (SMD) is a measure of effect size reported for continuous outcomes such as lab values (Interpreting Estimates of Treatment Effects). It is the difference in the mean between groups relative to their pooled standard deviation. It is also known as Cohen’s d.
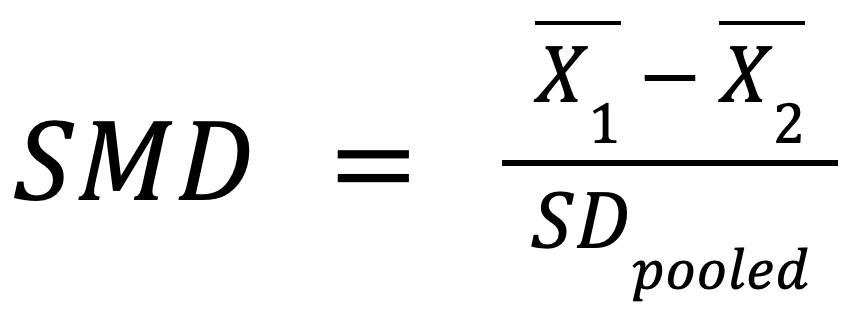
Because the difference in means is standardized by the pooled standard deviation, we can apply a rule of thumb to consider SMD as small, medium or large if the value is less than 0.2, 0.5 or 0.8 respectively. SMD = 0 would mean there is no difference. If group 1 received an intervention and group 2 was a non-intervention (control) group, a positive SMD indicates that the outcome tends to have higher values in the intervention group, and a negative value indicates that the outcome tends to have higher values in the control group.
Odds
Odds measure the likelihood that an event will occur. Mathematically, it is the ratio between the probability that the event will occur (i.e. p) and the probability that the event will not occur (i.e. 1-p).
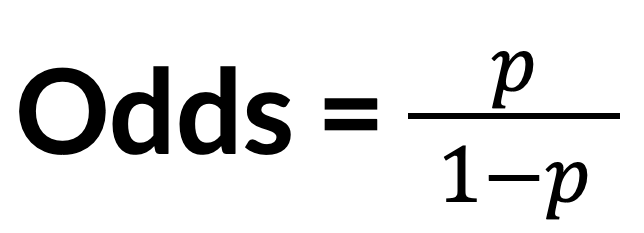
For example, out of a study with 30 patients, 6 patients have an outcome event. Then, the probability that a patient has the event is 6 / 30 = 0.2. Conversely, the probability of not having the event is 1 - 0.2 = 0.8; so, the odds of having the event is 0.2 / 0.8 = 0.25.
Odds ratio
The odds ratio (OR) measures the strength of association between exposure and binary outcome (e.g. fracture occurring or not). The OR is the odds that an outcome will occur given a particular exposure, compared to the odds of the outcome occurring in the absence of that exposure.
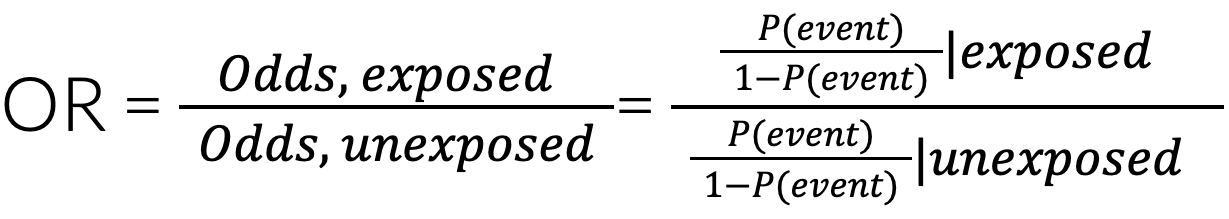
An OR > 1 indicates that exposed subjects have higher odds (i.e., are at a higher risk) for the outcome compared to the unexposed. Conversely, an OR < 1 suggests that the exposure is protective against the outcome. An OR of 1 would be interpreted as no association between exposure and outcome.
Hazard
Hazard, h(t), is the instantaneous rate of an event (e.g. death) at time t, given that N(t) persons have survived up to time t. The higher the hazard rate, the higher the risk of the event.
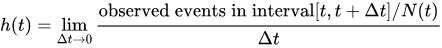
A hazard is the rate at which a person experiences an event within the very short (infinitesimally small) time period between (t) and (t + Δt), assuming they are at risk for the event at time t.
Hazard ratio
Intuitively, the hazard ratio (HR) can be interpreted as a measure of how often a particular event happens in one group compared to how often it happens in another group, over time (Cancer.gov). Strictly defined, HR compares the hazard of an event (e.g. death) in the exposed group with that of the unexposed.
Note that hazards are rates (i.e. events per unit time) so HR compares the relative rates of events between the exposed and the unexposed. For example, a HR of 2 for death does not necessarily mean that twice as many of the exposed died nor the exposed died in half the time. Instead, HR is interpreted as that the exposed has twice the probability of dying at a instantaneous moment in time compared to the unexposed (Spruance et al 2004), among the people at risk of dying at that moment in time.
A key difference between the hazard ratio and measures such as the odds ratio (OR) or relative risk (RR) is that the OR and RR compare odds/risks only at a single time point (generally, as of when people are no longer being observed in a research study). The HR is an average of the hazard rates throughout the whole study. Because of this, hazard ratios are often better able to handle
censoring in research studies. Censoring happens when people may drop out of a study before the study’s end and their outcomes are no longer observable. This can cause bias in end-of-study measures such the OR or RR. HR is typically reported as part of a time-to-event or survival analysis using Cox Proportional Hazards regression.
To reiterate, HR = 1 means that there is no difference in event risk between the two groups being compared. When HR > 1, the exposed group is at greater risk of the event than the exposed. In such a case, the Kaplan Meier survival curves diverge with the exposed curve steeper than the control curve, providing qualitative visualization to help interpret HR. When HR <1, the exposed group is at lesser risk than the unexposed.
Incidence Rate
Incidence rate is the number of outcome events occurring within a given time. An incidence rate includes a measure of time in the denominator, e.g. “2 events per year” or “120 cases per 10,000 person-years”.
Incidence Rate Ratio
Incidence Rate Ratio (IRR) compares the incidence rate of discrete outcome events (e.g. number of visits in a year) among the exposed relative to the unexposed, accounting for the duration of time each group contributed to the study.
IRR > 1 indicates that the numerator (i.e. exposed) group has more events than the denominator (unexposed) group. An IRR of 1 indicates identical event rate between the two groups.
Measures of Significance
P-value
A p-value, or probability value, describes how likely your data would have occurred by random chance because of how you sampled your study population. A p-value estimates the probability of getting a result at least as large (or as small) as found in a particular study, assuming there is no true effect in the population. A lower p-value means that it is less likely that your study result is due to random chance. Typically, a p-value of <0.05 is considered “statistically significant,” meaning that the finding is unlikely to be due to chance, however this threshold has historically been chosen arbitrarily.
For example, suppose a study estimated an odds ratio of 2.5 for the effect of smoking on heart attacks, with a p-value of 0.33. The p-value suggests that, assuming there is no true connection between smoking and heart attacks, if you were to repeat the study many times, you would get an odds ratio of at least 2.5 in 33% of those studies.
The p-value should be interpreted with caution. It does not indicate the size or clinical significance of the observed effect. It is quite common to look at a p-value < 0.05 as statistically significant (and p >= 0.05 as not statistically significant); this is only a convention, and should not be applied indiscriminately. A “statistically significant” p value can correspond to a miniscule or clinically insignificant finding (e.g. a blood pressure difference of 0.25 mmHg). Also, it is important that statistical significance should be interpreted along with clinical significance to draw meaningful conclusions (Wikipedia - misuse of p-values). In most situations, confidence intervals should be used along with p-values (Confidence interval or p-value?).
Confidence interval
A confidence interval (CI) provides information about the uncertainty around a particular estimate (such as an odds ratio). The CI suggests how much our estimated odds ratio might differ if we repeated our study with a different random sample from the population. .
For example, the association between an intervention on an outcome may be reported as an odds ratio of “0.78 (95% CI: 0.66-0.96)”. This means that the estimated odds ratio in this sample was 0.78; if the test was repeated with other samples from the same population, we expect the estimated odds ratio to fall between the 95% CI 0.66 and 0.96 95 times out in every 100 trials.
Closely related to CI is the p-value which also provides information about the uncertainty associated with a particular estimate. The CI has a few advantages relative to the p-value: the CI is represented on the same scale as the point estimate; the CI also measures the direction and strength of the estimated effect.
E-value
E-value measures the robustness of effect sizes against residual confounding (see Confounding) caused by confounders that were unmeasured or could not be controlled within the analysis (VanderWeele & Ding, 2017). For a single hypothetical variable, it calculates how strongly that variable would have to be associated with both the treatment and the outcome in order for that variable to fully explain the estimated treatment effect.
A large E-value (>2) implies an effect estimate is less likely to be caused by residual confounding, because it would require considerable residual confounding to overcome the effect. As one must be cautious of drawing causal inferences from observational studies, which are subject to data missingness, mismeasurement, and confounding, the E-value provides investigators another measure of the plausibility of the observed effects.
There are no clear delineations or standards for what constitutes a ‘robust’ E-value, however generally statistics with E-values < 1.5-1.8 are considered ‘fragile’ and may have confounding affecting the result.
Comorbidity score
The Charlson Comorbidity Score was developed to predict a patient’s risk of dying within the next year based on the number and severity of different comorbidities. The score was developed and validated by Charlson et al in 1987. The score is a weighted sum of 17 comorbidities, factoring the number and severity of comorbidities and age such that the final score provides a straightforward and reasonable way to stratify mortality risk.
Since its inception, it has been widely adopted by epidemiological studies as a way to summarize health status in terms of existing health conditions and their severity. While several alternative instruments exists, the Charlson comorbidity score remains one of the most popular for its openly available algorithm (also supported by R, Python, SAS) and evolving adaptations to the increasing use of administrative billing codes in both ICD9 and ICD10 (Deyo et al. 1992, Halfon et al. 2005, Quan et al. 2005).
We used the most common approach to calculate Charlson score in recent times. First, we defined 17 comorbidities according to ICD9 and 10 codes by Quan et al. 2005. The comorbidities are then summed according to the updated weighted scheme by Deyo et al. 1992. This computation could predict in-hospital mortality with high accuracy (Quan et al. 2005).
Measures of follow-up time
In survival analyses, there are multiple ways to summarize how long subjects were under observation as part of the study.
Median survival time
Median survival time is one measure of the “average” time until study subjects experience a specific study outcome. It is defined as the amount of time that has elapsed when 50% of study subjects have experienced the study outcome. For example, if the outcome of interest is infection with SARS-CoV-2, median survival time is the number of days (or years) required for 50% of subjects to become infected. If multiple survival outcomes are defined for an Atropos Health analysis, each one will have a separate median survival time.
Importantly, median survival time is not defined if less than half of study subjects experience the outcome of interest.
Restricted mean survival time (RMST)
RMST is another measure of the “average” time until study subjects experience a specific study outcome. However, unlike median survival time, RMST can always be defined, even if fewer than half of subjects experience the outcome of interest. RMST is calculated as the mean event-free survival time from the start of follow-up until some cut-off time (Han et al, 2022). In Atropos Health studies, we use the longest observed follow-up time as the cutoff. As with median survival time, each separate outcome will have its own RMST when there are multiple survival outcomes.
Median follow-up time
Median follow-up time is the median number of days (or years) that study subjects were observed in the context of the current study. This is commonly reported in observational studies involving survival analysis (see the STROBE reporting guidelines, for example).
Statistical concepts
Observational studies
These are studies in which the investigator observes patients, but does not intervene in their treatment or healthcare. Unlike clinical trials, investigators in an observational study do not assign patients to different treatment groups.
At Atropos Health, we focus on observational studies to generate real-world evidence from real-world data. One key advantage is that observational studies are fast because they draw on data already collected during the course of routine clinical care (e.g. electronic health records). Its key disadvantage is that, unlike clinical trials that randomize treatment assignment and cancel out baseline differences (i.e. confounders) between groups, observational studies lack that mechanism and will require Causal Inference methods to control confounding and determine whether associations are causally related and not mere correlations.
Causal inference
Causal inference is the process of determining whether associations between variables in a research study reflect true causal relationships in the underlying population. As an example, consider the causal diagram below where we wish to understand the link between alcohol and death.
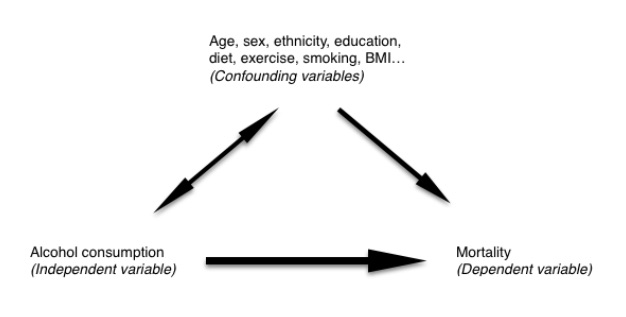
A study might find that alcohol consumption is associated with a higher rate of mortality. To establish that alcohol consumption actually causes (denoted by ->) death, several proposed criteria (Hill 1965) must be fulfilled such as:
- Temporality (i.e. alcohol consumption came before death)
- Specificity (nothing else accounts for the alcohol -> death relationship)
- Dose-response relationship (changing alcohol consumption should also change the death rates)
Confounding
Confounding refers to a spurious association between an intervention and an outcome because a third variable is independently associated with both (cochrane.org). This third variable is called a “confounder.” Confounding is an important source of bias in observational studies and must be addressed with causal inference before drawing conclusions.
In the above causal diagram example, our data may suggest that people who consume more alcohol are more likely to die. There may be other factors that may attenuate or even reverse the effect we find. People who consume more alcohol may also tend to smoke. These people could have a higher death rate than people who consume less alcohol because they are smokers rather than because of alcohol. Here, smoking is a confounder that influences alcohol’s association with death.
Observational studies can have two types of confounders:
- Measured confounders (e.g. age) that are collected in our data and known to potentially influence an outcome, should be accounted for in the study design and analysis.
- Unmeasured confounders that are not available (e.g. pollution exposure),unknown, or cannot not be practically included or measured in the study.
To overcome the effect of confounding and assess the true relationship, we can apply confounder control methods such as appropriate study design, matching on baseline variables, stratification and multivariable regression. These methods only remove the effects of measured confounders, however.
Residual confounding
In real-world studies, situations arise where the effect of confounding cannot be adjusted entirely, leading to residual confounding. Residual confounding can come either from unmeasured confounders or from incomplete control for the effects of measured confounders.
Here, we additionally compute an E-value (above) to assess the likelihood that observed results could be attributed to residual confounding.
Basic matching
A simple way to control for confounding is to match the exposed and unexposed groups by their demographics such as age and sex. By default, basic matching in our studies matches the groups by age and sex but these can also include other confounders upon request. Briefly, selected p confounders form a p-dimensional space in which patients are described by these p confounders. Two patients are said to be similar in confounders when their Mahalanobis distance in this p confounder space is small (caliper < 0.25).
Propensity score matching (PSM)
Propensity score matching (PSM) is a confounder control method used in observational cohort studies where the exposed and unexposed groups may have underlying differences (e.g. those exposed to statins have underlying heart conditions and may be sicker than the unexposed group). PSM statistically balances the pre-exposure differences such that the groups being compared are as similar as possible except for their exposure assignment.
Propensity scores (PS) are generated from a logistic regression model where the treatment assignment is predicted by the pre-treatment covariates as explanatory variables.
log PS / 1-PS ~ pretreatment covariates where PS = probability of treatment
After balancing the two groups by matching on nearest PS within a distance caliper, these matched groups are then followed for their outcomes such that any outcome differences can be attributed to the treatment (and plausibly residual confounders if any). Residual confounding may arise because the PS model may not perfectly explain the measured confounders and some confounders may remain unmeasured (e.g. smoking status is unavailable or not specified to be a confounder).
At Atropos Health, we use high dimensional propensity scores (hdPS, Schneeweiss et al. 2009) which controls for a large number of confounders (e.g. demographics, ICD, CPT, drug codes) simultaneously between the exposed and unexposed. The candidate covariates identified by hdPS are then fitted to a propensity score model using the lasso logistic regression (Franklin et al. 2015, Low et al. 2016) and applying machine learning best practices (5-fold cross validation, pg 241, 1-standard error rule, pg 61). Such rapid machine learning models allow us to perform large-scale cohort studies while controlling for a large number of confounders.
Inverse Probability of Treatment Weighting (IPTW)
An alternative to propensity score matching is Inverse Probability Treatment Weighting (IPTW). Unlike PSM that matches treatment and control patients based on their propensity scores and discards the unmatched patients, IPTW uses the entire cohort but weighs each patient according to the inverse of their PS such that confounders underlying the PS will be balanced between treated and untreated groups.
In our implementation of IPTW, we first compute hdPS as in Propensity Score Matching above. However, instead of using the propensity scores for matching, they are used for weighting each patient’s contribution to the final outcome regression model. We use stabilized weights (Austin & Stuart 2015) to ensure that the pseudo-population created from these weighted patients is the same size as the original cohort with similar statistical power.
Censoring
In statistics, censoring is a condition in which the value of a measurement or observation is only partially known. For example, out of a group of patients in a study, some patients may choose to discontinue, or may be lost to follow-up. We do not know what happened from the time they dropped out to the end of the study period. Time-to-event analysis treats them as being right-censored (i.e. duration is more than the observed time) and allows us to use all the data rather than exclude them from analysis which may wrongly estimate the duration and risk of the event.
Competing risks
Classical survival analysis focuses on a single type of event, ignoring other events that may occur during the study period and prevent the primary event from being observed. For example, in a study of association between immune suppression drugs and diagnosis of glioma in cancer patients, death would be considered a competing event. Glioma cannot be observed after a patient dies, hence the time at risk is curtailed.
In studies where competing risks may be important, we present two types of analyses: (i) a cause-specific Cox proportional hazards regression model that censors competing events prior to estimating hazard ratios, and recommended for etiological studies (Schuster et. al, Journal of Clinical Epidemiology, 2020), and (ii) a subdistribution Fine-Gray hazard model that is useful in prognostication / prediction of the primary event (Austin et. al, Circulation, 2016, Austin et. al, Statistics in Medicine, 2017).
Time-dependent Cox proportional hazards regression
Sometimes exposure varies over time or may be conditional on waiting for the exposure. For example, ESRD patients may wait until an organ becomes available for transplant (intervention) and are compared to other ESRD controls without a transplant. In such a comparison, the waiting time for one group is known as immortal time, creating a specific type of selection bias known as immortal time bias. To avoid such bias, we can modify our standard pipeline to use time-dependent Cox regression such that the exposure covariate is specified to vary over time and to start after the waiting period.